LeLaN: Learning A Language-conditioned Navigation Policy from In-the-Wild Videos
Abstract
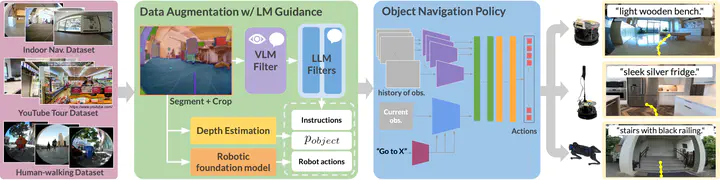
The world is filled with a wide variety of objects. For robots to be useful, they need the ability to find arbitrary objects described by people. In this paper, we present LeLaN (Learning Language-conditioned Navigation policy), a novel approach that consumes unlabeled, action-free egocentric data to learn scalable, language-conditioned object navigation. Our framework, LeLaN leverages the semantic knowledge of large vision-language models, as well as robotic foundation models, to label in-the-wild data from a variety of indoor and outdoor environments. We label over 130 hours of data collected in real-world indoor and outdoor environments, including robot observations, YouTube video tours, and human walking data. Extensive experiments with over 1000 real-world trials show that our approach enables training a policy from unlabeled action-free videos that outperforms state-of-the-art robot navigation methods, while being capable of inference at 4 times their speed on edge compute. We open-source our models, datasets and provide supplementary videos on our project page.